We read two papers last Thursday: the “DRAW” paper by Gregor et al, 2014 and the “Show, Attend, Tell” paper by Xu et al, 2015. Both embed an attention model in deep neural networks (DNNs). The first paper generates images that attempt to match the distribution of input images while the second paper generates captions for images. With the attention model, both models output data over multiple time steps, focusing on one region of the image per step. To implement this sequential generative process, both models used long short-term memory units (LSTMs) as one layer of the network.
DRAW: A Recurrent Neural Network For Image Generation
This paper is based on the following two ideas: a) the generation of an image should be refined in multiple steps; and b) in each of multiple steps of refinement, the model should focus its attention only on as small region of the image.
As a DNN, the model is a combination of an LSTM and an auto-encoder. Model representation of the draw model is shown in the following image (Fig. 2 of the paper).
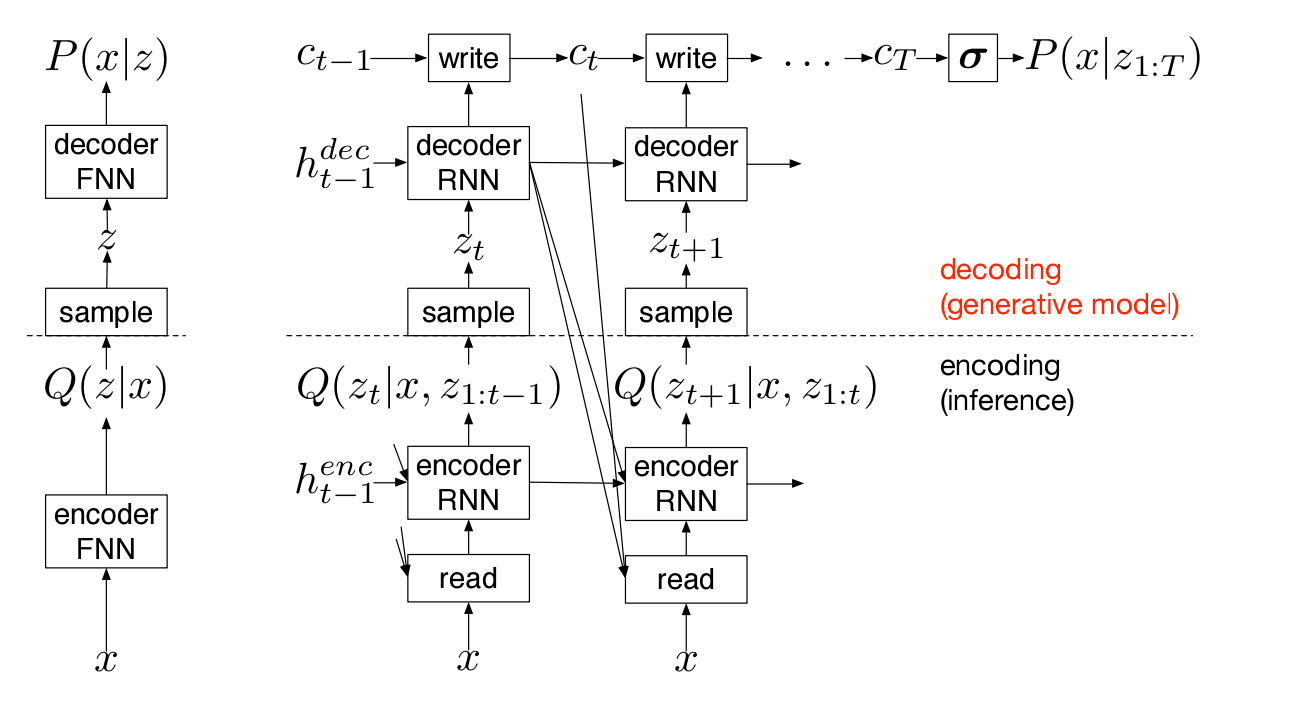
At each time step, data passes vertically from the bottom to the top.
- Input: and , (the latter is the residual of the last step’s fitting)
- Read: The attention model controls what to read. An Gaussian filter is positioned over the image to filter the input image. Five parameters are used to control the position, area, effective resolution, and intensity of the attention. The parameters are conditioned on the decode output at the last step.
- Encoding: The data read in by the attention layer is encoded
- Code: the distribution of the code should be similar to a latent prior
- Decoding: The code z is decoded though the generative process
- Write: the decode output sets the attention model, and the data is written through filters of the attention model. The usage of the filters here is in the reverse order of that in the read step.
Over time steps, the model is linked in the following ways.
- The input includes the residual of the last step’s fitting result.
- The parameters of the attention model are controlled by last step’s decoding output.
- The last step’s decode output is also fed into the current step’s encoding module.
- The last step’s write-out data is added to that of the current step. The sum of all write-outs reconstructs the input image.
The training objective is to minimize the reconstruction loss and the KL divergence of the latent prior to the encoding distribution .
The paper shows interesting results in several tasks. In the image generation task, the generation process does exhibit some progressive refinement, though still different from the way we humans draw digits.

(Also check animated results from Eric Jang’s blog link)
The model improves the predictive log-likelihood over that of competing models including the auto-encoder. In the task of identifying numbers in cluttered images, the model often correctly focus its attention to the numbers.
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
The argument of the paper is that the attention moves in the image as the caption generation for the image proceeds in steps.
The model structure is an LSTM. The inputs of the model are feature vectors extracted from image regions by CNN. The fitting targets are embeded vectors of words in training captions. The attention model, which lies between the input and the LSTM units, selects only the feature vectors of some regions.
The attention model calculates a set of probabilities for current locations with a multilayer perceptron conditioned on previous hidden state.
The context vector (the input to the LSTM) is calculated with either hard attention or soft attention.
Hard attention: the attention location at every step is a categrical r.v. and thus is a hidden variable.
( is an indicator one-hot variable)
The model maximizes a variational lower bound of the log-likelihood, which is optimized by stochastic gradient method. Moving average and other techniques are used to control the variance of gradients.
Soft attention: the attention locations are weighted by the probability vector.
The input is a weighted sum of feature vectors at different locations. The model can be optimized by back-propagation.
Extra constraint: every location should be focused on at least once during the generation process. Few regions can be totally neglected with this constraint.
The paper shows significant improvement of BLEU score over that of previous methods on several caption generation tasks. In their example images, the chosen locations of attention seem to make sense. Figure 5 of the paper (reproduced below) shows several good examples.

References
[1] Gregor, Karol, et al. “DRAW: A recurrent neural network for image generation.” arXiv preprint arXiv:1502.04623 (2015). link
[2] Xu, Kelvin, et al. “Show, attend and tell: Neural image caption generation with visual attention.” arXiv preprint arXiv:1502.03044 2.3 (2015). link
[3] Eslami, S. M., et al. “Attend, Infer, Repeat: Fast Scene Understanding with Generative Models.” arXiv preprint arXiv:1603.08575 (2016). link
[4] Mnih, Volodymyr, Nicolas Heess, and Alex Graves. “Recurrent models of visual attention.” Advances in Neural Information Processing Systems. 2014. link