Two papers this week proved convergence results for optimizing non-convex loss functions using stochastic gradients. In The Landscape of Empirical Risk for Non-convex Losses by Mei, Song, Yu Bai, and Andrea Montanari, 2016 [1], the authors show that while empirical risk for squared loss is non-convex for linear classifiers, there are numerous desirable qualities once we reach a certain sample size, namely exponentially fast convergence to a local minimum (which is also the global minimum). In Deep Learning without Poor Local Minima by Kawaguchi (2016) [2], by reducing deep linear networks to deep nonlinear networks, the author shows that, among other things, every unique minimum is a global minimum and every non-minimum critical point is a saddle point.
The Landscape of Empirical Risk for Non-convex Losses
While non-convex optimization has historically been associated with NP-hardness, there are a plethora of non-convex functions that can be optimized more easily by taking advantage of some special structural properties. This paper focuses on the specific case of noisy linear classification, and shows that under certain assumptions, the empirical risk, which is non-convex, has a unique local minimum, which gradient descent approaches exponentially fast.
Setup
- Data is i.i.d.
- for some function, , which is known.
- Loss function is empirical risk .
We note that the empirical risk is non-convex. However, the authors argue that non-convex losses can be beneficial for this task because they are unbounded, they have a smaller number of support vectors, and models that use non-convex losses (such as neural networks) have been quite effective.
The true risk, is convex in terms of , and the authors show that the empirical risk function ends up sharing many of these nice properties. The following graph shows three possible scenarios for the empirical risk. On the left is a function with many local minima, and in the center is a loss with local minima that are close to the risk global minimum. Niether of these are ideal, and we will see for sufficient sample data, the function behaves like the graph on the right with a local minimum that is the risk global minimum, verifying the effectiveness of stochastic gradient descent.

We make the following assumptions:
- is three times differentiable, where and the first three derivatives are bounded.
- The feature vector X is sub-Gaussian, i.e. for all , .
- spans all directions in so for some .
Assumptions 1 and 3 appear reasonable. The assumption that deserves the most scrutiny is assumption 2, as indeed, it guides many of the proofs in the paper. We note that if is bounded, assumption 2 holds.
Results
The main result of this paper is Theorem 1 which has three parts. If for some constant ,
- has a unique local optimizer, which is also global. This implies no other critical points exist.
- Gradient descent converges exponentially fast.
- The global optimum of the empirical risk converges to the true minimum :
Looking at , is roughly the same scale as , and becuase cannot be less than , these results are ideal.
The authors verify these results by running experiments with simulated data and various conditions for . These results verify that once crosses some critical threshold, the convergence results change dramatically.
Proof Ideas
We discuss a few theorems the authors develop to construct their proof (which is too technical to include in this writeup). The meat of their argument lies in Theorem 2, which conerns the true risk . Summarizing these results,
- The true risk has a unique minimizer .
- The Hessian of has bounds, where in a small ball around the the global optimum, we have a strongly convex function (i.e. we converge very quickly):
- The gradient of has bounds, such that when we are outside of a ball centered at the true value , the gradients are non-zero:
Namely, this implies our gradients point toward the optimum.
The remaining theorems in the paper bound the probabilities that the gradient and Hessian of empirical risk differ from the true risk by a constant. Combining these probabilities with Theorem 2, the authors conclude that the desirable qualities are recovered with a high probability when using the non-convex empirical risk, as opposed to true risk.
Discussion
We were curious whether the proofs can generalize to functions beyond squared loss, since in real life squared-loss isn’t the most frequently used loss for classification.
Overall, we thought this was a very well-written paper that did a good job of stating the high-level at the beginning, while exploring the technical details throughout.
Deep Learning without Poor Local Minima
The key assumption of this paper is that, under certain conditions, deep linear neural networks are similar to deep nonlinear neural networks. The author proves four optimization results for deep linear neural networks, and via a reduction, shows that these extend to nonlinear neural networks.
Setup
Our data is of the form , where, for some weight parameters and a nonlinearity , our predictions for a nonlinear network take the following form:
We use squared loss: , where is the Frobenius norm. It has been proven that this optimization is NP-hard. However, for now, let’s assume a deep linear network. That is, , so
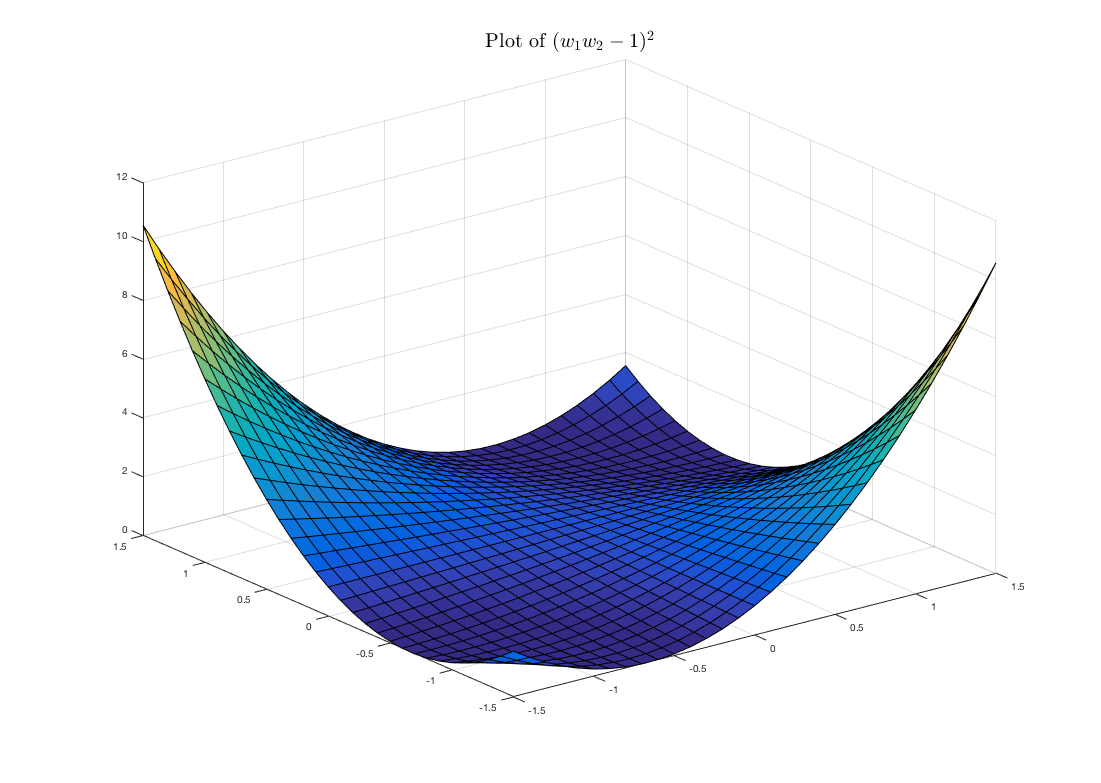
The author shows that this function is non-convex in the product of the weight matrices. As an example, take the simplest case, where , and we have weight scalars and . The plot below depicts our loss function . As we can see, even in the simplest case, there are infinite global minima when , in addition to saddle points.
Results
The main result for deep linear networks is in Theorem 2.3. Here, under reasonable assumptions for the rank of our data, for any depth and the smallest width of a hidden layer, the loss function has the following properties:
- It is non-convex and non-concave.
- Every local optimum is global.
- Every critical point that is not a global minimum is a saddle point.
- If Rank(, then the Hessian at a saddle point has at least one negative eigenvalue.
We note that a Hessian having at least one negative eigenvalue is “nice”, in that it implies there are no flat regions in the function. Briefly, the proof ideas are as follows. For 1, if we set one entry to 0, the product is fixed at 0, meaning that the function doesn’t change in , implying non-convexity. For 2, we rely on the notion of a “certificate of optimality”; that is, we check that at every local minimum, , implying the local optimum is global. 3 follows naturally from 2, and 4 is somewhat technical. For the full proofs, refer to the original paper [2].
We next focus on a reduction from nonlinear neural networks to linear neural networks. Here, we take as the hinge loss, i.e. . Taking advantage of a neural network’s graphical strucutre, the author notes we can rewrite the objective by summing over all possible paths, introducing a binary random variable to denote those that are turned “on” by the activation function. Specifically, we can write the following, where is a normalization constant and is the toal number of paths from the inputs to each output:
Now, we introduce the central assumption of the paper: Each is independent of , and is a Bernoulli random variable with a global probability . Thus, replacing the with in the above equation reduces this loss to that of a deep linear neural network, so all the results from Theorem 2.3 hold.
We spent a lot of time discussing how realistic this claim is. We note that it improves upon previous work, which had stronger assumptions and proved weaker results. However, it appears suspicious that all the are i.i.d. random variables, and this claim should receive scrutiny.
All-in all, we thought this was a well-organized paper that outlined intuitive and important theoretical results for deep neural networks.
References
[1] Mei, Song, Yu Bai, and Andrea Montanari. “The Landscape of Empirical Risk for Non-convex Losses.” arXiv preprint arXiv:1607.06534 (2016). link
[2] Kawaguchi, Kenji. “Deep Learning without Poor Local Minima” arXiv preprint arXiv:1605.07110 (2016). link …