On our reading list for this week we had the paper by Advani and Ganguli titled “Statistical Mechanics of Optimal Convex Inference in High Dimensions” [1]. Classical statistics gives answers to questions on the accuracy with which statistical models can be inferred in the limits where the measurement density is . In this work the authors are concerned with the analyses of the fundamental limits in the finite regime which is the “big data” regime where both the number of data points and the number of parameters tend to infinity but their ratio is still finite.
Statistical Mechanics of Optimal Convex Inference in High Dimensions
For their analysis authors use the ubiquitous statistical inference procedure, regression: . More specifically in their analysis they consider the class of inference algorithms known in the statistics literature as M-estimators:
In this setup and yields the ML estimate while setting and gives the MAP estimate. As we noted in the reading group this class of estimators doesn’t include Bayesian inference of the posterior mean.
Analysis is focused on the behavior of the error in estimating the signal and the noise .
Review of classical statistics regime where
In classical statistics regime we have the Cramer-Rao (CR) bound which is the lower bound on the error of any unbiased estimator:
Where, is the Fisher information:
Statistical Mechanics
The general idea is to solve
for generic convex an by:
-
Defining a physical system augmented with an inverse temperature whose ground state is a solution to the problem as . The energy in terms of is:
-
Calculating the free energy of the system using the replica trick.
A physical system in the micro-canonical ensemble minimizes . A physical system in the canonical ensemble (held at constant temperature ) minimizes the free energy:
-
Taking the limit.
The general idea of the replica trick is to calculate an average over a polynomial of instead of an intractable function of . The free energy is calculated using:
Where is the partition function of “copies” of the system. The integral over , and couples these copies. This interpretation is valid for integer , but the formula is taken to hold for continuous . We get:
Where
In the replica symmetric (RS) approximation the assumption is that the variables can be replaced by four variables in the form . This is a mean field assumption on the interaction between the replicas. Details about the validity of this assumption are given in [2]. The results are:
Where:
Inference Without Prior Information
If we can’t utilize prior information, then we set which gives and the equations reduce to:
Optimal error in the finite regime
What is the optimal error in this setting? We can rewrite the equations as:
Then after some algebra that eliminates the terms we can obtain:
Notice that the bound is higher than the Cramer-Rao bound due to the additional noise added to from .
Optimal cost
One can look for that achieves by adding these constraints to a Lagrangian that minimizes the error:
Then by solving the Euler-Lagrange equation , and inverting the Moreau envelope we obtain:
Where is the PDF of .
Figure 4 from the paper (shown below) gives a comparison summary of the generalization (a) and training (b) error of the optimal unregularized M-estimator with ML and quadratic loss functions. It shows over-fitting as . Optimizing over is analogous to optimizing over and not .

Inference With Prior Information
We start with the often used quadratic loss and regularization: , and .
As we have seen, for we have the simplification:
The four equations reduce to:
From the first two equations one obtains:
The optimal regularization is given by solving , which gives . This means that high SNR requires little regularization. Plugging this into the remaining equations, we solve for :
This exhibits a phase transition, which in high SNR reduces to:
-
if :
-
if :
-
if :
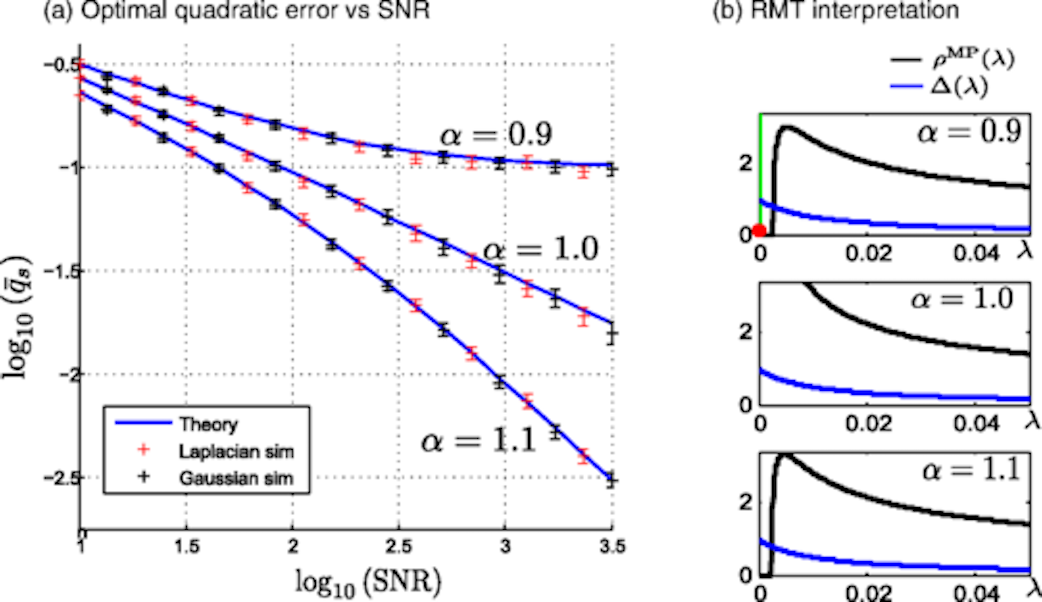
Shown below is Figure 5 from the paper where we observe that approaches a constant when .
Optimal Inference with non-Gaussian Signal and Noise
Generalizing the unregularized case, the optimal cost and regularizer is found to be:
Where:
References
[1] Madhu Advani and Surya Ganguli. “Statistical mechanics of optimal convex inference in high dimensions”, In Physical Review X, 6:031034 (2016). link
[2] Advani, Madhu, Subhaneil Lahiri, and Surya Ganguli. “Statistical mechanics of complex neural systems and high dimensional data.” Journal of Statistical Mechanics: Theory and Experiment 2013.03 (2013): P03014. link