This week, we read Gal and Ghahramani’s “Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning” [1], as well as “Deep Networks with Stochastic Depth” by Huang et. al [2]. The two papers differed greatly in scope: Gal and Ghahramani looked at Dropout from a Bayesian point of view and cast it as approximate Bayesian inference in deep Gaussian Processes while Huang et al. demonstrated the possibility of incorporating Dropout in the Resnet architecture.
The figures and tables below are taken from the aforementioned papers.
Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning
Generally, standard deep learning tools for regression and classification do not capture model uncertainty. But having estimates of model uncertainty is important when deploying deep learning and deep reinforcement models as given such estimates, we would be able to treat uncertain inputs and special cases with greater care in the former and learn faster in the latter. Here, Gal and Ghahramani show that Dropout can be understood as approximate Bayesian inference in deep Gaussian Processes and hence model uncertainty can be captured under the Bayesian framework.
Setup
- Observed inputs and outputs
- Set of model parameters
- Define prior distribution over as and likelihood as
- We want to find the posterior
Moving to the Bayesian neural networks world, we define the weights and bias to be part of the model parameters but in this analysis we omit for simplicity. For the weights linking the and layers: we represent it as matrix of dimension where is the number of nodes in the layer. With this in place, set a prior for layer and column . We now have .
Here, we use the commonly defined loss function for dropout
Variational Inference
We use variational inference to approximate the posterior with . Our loss function is then in the form of
and the first term can be approximated by MCMC integration which gives an unbiased estimator. Define the approximated as .
Moving on to , given variational parameters we set our approximate posterior as
where . As we are working in continous space, we approximate the functions with where .
We can also look at this in terms of a generative process.
For every round of minimisation:
- Sample for each layer and column
- Set ). Note that this sets columns of to , which is equivalent to dropping out the unit in the layer
- Minimise w.r.t to
With the above in place, we now approximate the term within as (see the appendix [3] for proof). Putting it all together, we have
which looks exactly like .
After obtaining the posterior, we can estimate the approximate predictive distribution using Monte Carlo methods.
Results and Discussion
The following figure demonstrates the uncertainty estimates produced by the approximate posterior distribution
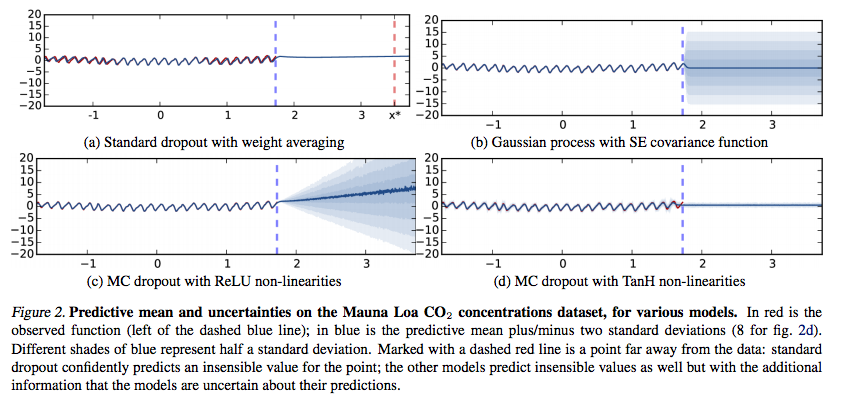
and the table below shows that the above method leads to superior predictive performance on almost every dataset
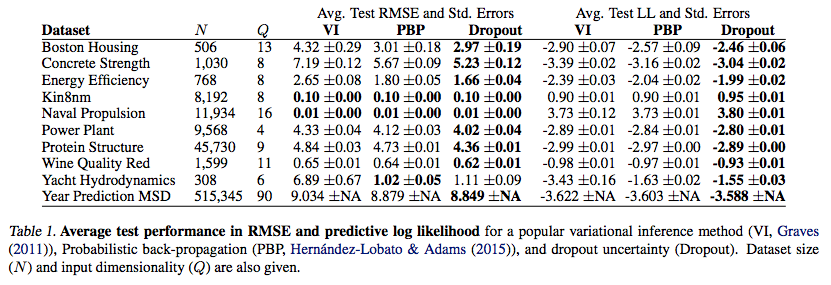
Lastly, this figure shows the speed up in learning rate for reinforcement learning
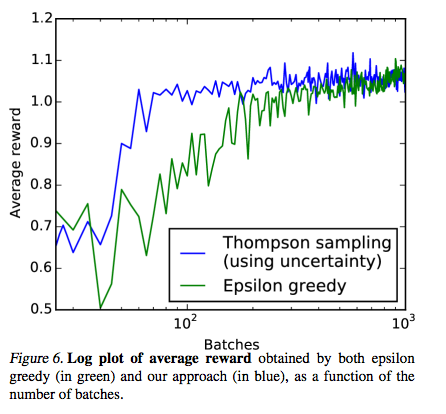
The authors postulated that the improved results was due to the model fitting the distribution that generated the observed data and not just its mean and remarked that the many Bernoulli draws in was a cheap way of obtaining a multi-modal posterior.
Deep Networks with Stochastic Depth
The premise of Huang et. al’s paper was to address the problems of training very deep networks: vanishing gradients, dimnished forward flow and long training times. Essentially, in the case of of Resnets, the authors demonstrate that dropping out entire layers to train short networks and using deep networks at test time leads to state-of-the-art results in most image datasets.
ResNet Primer
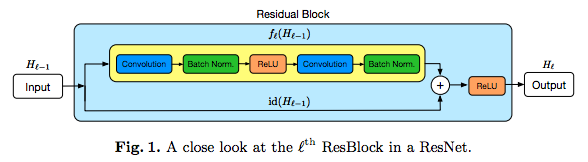
Resnets are composed of residual blocks (ResBlocks) with blocks having the update rule . The above figure shows a schemantical representation of a block with defined as a sequence of Conv(olution)-B(atch)N(ormalisation), or ReLu-Conv-BN layers. Such a scheme was used in all experiments in the paper.
Stochastic Depth
The gist of stochastic depth is to shrink the depth of a network during training and keep it unchaged during testing. This is done by skipping out entire ResBlocks during training using skip connections. Define as Bernoulli r.v. indicating that the -th ResBlock is active () and inactive () and the survival proability as . By multiplying by , we can drop the whole block out if is set to , which results in
In this setting, we have as a new hyperparameter. As earlier layers extract low-level features and should be present most of the time, a simple linear rule from for the input to for the last ResBlock is
This modification reduces the depth of the network as the expected network depth is , which also results in training time savings. Huang et. al also characterise the different sets of ResBlock for each minibatch as an implicit ensemble of ResBlock within the ResNet itself and postulates that such a configuration gives rise to better results. However, we are not very convinced by this claim based on what we know in classical ML.
During test time, the forward propagation update rule is
to account for the probability of each layer “surviving”.
Results
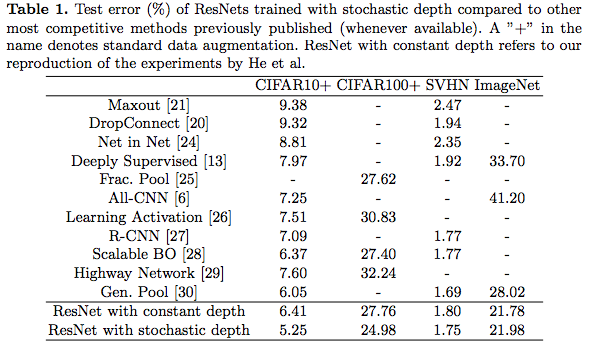
The table below shows that ResNets with stochastic depth tends to outperform other architectures on most image datasets apart from ImageNet
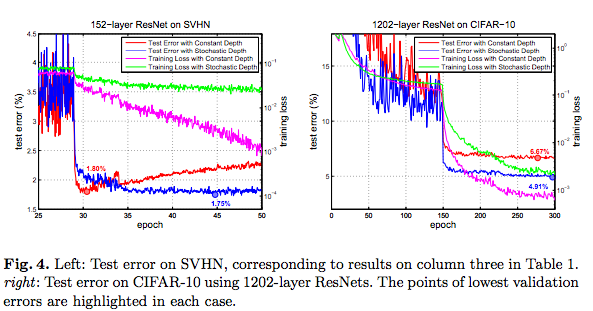
and following figure demonstrates that stochastic depth prevents overfitting in 1202-layer ResNet, giving rise to a network of more than 1000 layers further reducing the test error on the CIFAR-10 dataset.
[1] Gal, Y. and Ghahramani, Z., 2015. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. arXiv preprint arXiv:1506.02142. link
[2] Huang, G., Sun, Y., Liu, Z., Sedra, D. and Weinberger, K., 2016. Deep networks with stochastic depth. arXiv preprint arXiv:1603.09382. link
[3] Gal, Y. and Ghahramani, Z., 2015. Dropout as a Bayesian approximation: Appendix. link