This week we read and discussed two papers: a paper by Johnson et al. [1] titled “Composing graphical models with neural networks for structured representations and fast inference” and a paper by Gao et al. [2] titled “Linear dynamical neural population models through nonlinear embeddings.” Although the two papers have different focuses — the former proposes a general modeling and inference framework, whereas the latter focuses in particular on modeling neural activity — they are similar in that both use structured latent variable models as part of a variational autoencoder framework in order to perform inference. The benefit to this type of approach is that it allows for an increase in the flexibility of the models we can consider while retaining interpretability, even in high dimensions.
The figures and algorithms below are taken from the aforementioned papers.
SVAE — Structured Variational Autoencoders
We first discussed the paper of Johnson et al [1], which combined ideas from probabilistic graphical models and deep learning in order to propose a joint modeling and inference framework, which attempts to allow for flexible and interpretable representations of complex high dimensional data. Generally, probabilistic graphical models provide structured representations which are frequently inflexible, whereas (for example) variational autoencoders are able to learn flexible data representations but may not encode an interpretable probabilistic structure. Ideally, we would like to be able to combine the strengths of these two approaches and eliminate the weaknesses.
The general framework proposed by the paper in order to achieve this, which they refer to as the structured variational autoencoder (SVAE), can be broadly motivated as follows. In an exponential family latent variable model, we have efficient inference algorithms for when the observation model is conjugate; however, these algorithms depend on structures which break down when we do not have conjugacy. One particular way of handling non-conjugate observation models is by using the variational autoencoder, which introduces recognition networks in order to do so. The main idea of the SVAE is therefore to learn recognition networks that output conjugate graphical model potentials, so that they can be used in graphical model inference algorithms as a surrogate for the (non-conjugate) observation likelihood.
Notation and setup
Here we denote as our global latent variables and as our local latent variables. We then let be an exponential family and the corresponding conjugate, so
where by conjugacy we may write . We then denote our general observation model for the data as (for example, this may be obtained via some neural network) and let be a exponential family prior on . The aim is to then obtain (an estimate for) the posterior .
Variational inference
Fixing , we can consider the mean field family and the variational inference objective
in order to approximate the posterior. The authors then make some further restrictions:
- is restricted to belong to the same exponential family as with natural parameters ,
- is restricted to belong to the same exponential family as with natural parameters
- is restricted to belong to the same exponential family as with natural parameters
and denote the above variational inference objective as .
To efficiently optimize over this objective, one approach is to consider as a function of the other parameters. As may generally be intractable, this term in the objective is replaced by a term conjugate to the exponential family , and so is now selected by optimizing over a surrogate objective
where and is a parameterized class of functions corresponding to the recognition model. Defining
one can show that the corresponding factor is given by
Although is suboptimal for , this factor is at least tractable to compute.
The SVAE objective
The SVAE objective is then defined as
and it is this objective which the SVAE algorithm attempts to maximize. Proposition 4.1 of the paper shows that the SVAE objective is a lower bound for the mean field objective for any recognition model ; to provide the best lower bound, we will want to choose this class to be as large as possible.
The approach of first optimizing for as a local partial optima of has two computational advantages; firstly, by exploiting the graphical model structure, and expectations with respect to are quick to compute. Secondly, the natural gradient can be easily estimated; without going into the finer details, the natural gradient for SVAE is a sum of a the natural gradient in SVI, plus a term which is estimated as part of computing the gradients with respect to the remaining parameters.
For sake of completeness, the SVAE algorithm is reproduced below:

Experiments
In the paper SVAE is applied to a variety of synthetic and real data; we briefly highlight one of their experiments. Here, they use a latent linear dynamical system (LDS) SVAE to model a sequence of one dimensional images representing a dot bouncing from top to bottom of the image. The below figure shows the results from prediction at different stages of training; the top panel an example data sequence, the middle the (noiseless) predictions from the SVAE, the bottom the corresponding latent states, and the vertical line representing the training data. We can see that the algorithm is able to represent the image accurately (after sufficiently many training epochs).
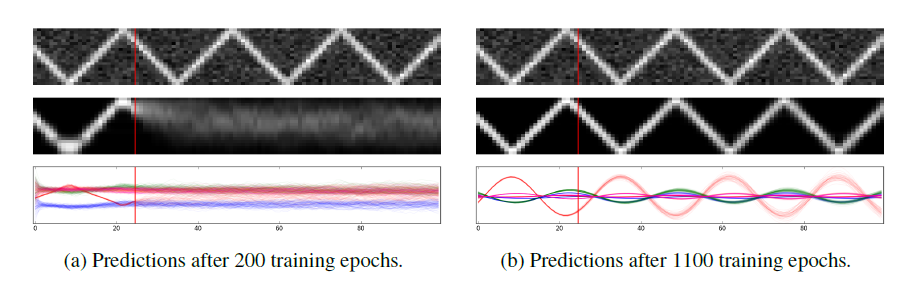
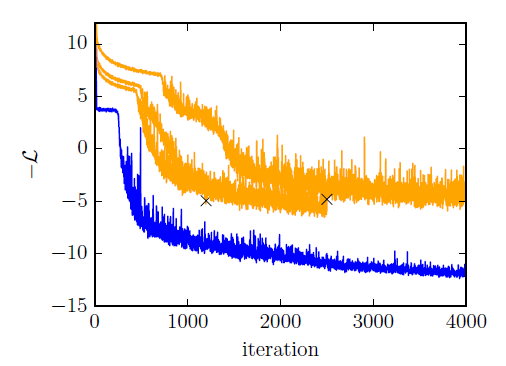
More importantly, this experiment illustrates how the natural gradient algorithm learns more quickly than that standard gradient descent, while also being less dependent on the parameterization. This can be seen in the figure below, which shows how evolves with iteration number when using natural (blue) and standard (orange) gradient updates (where X’s mark early termination), for three different learning rates.
fLDS - Linear dynamical systems with non-linear observations
We then discussed the paper by Gao et al. [2], which is similar to the first paper in that a latent variable approach is used, but here the authors focus on one problem — that of modeling firing rates of neurons. Here this is done by modeling these rates as an arbitrary smooth function of a latent, linear dynamical state. As in the SVAE paper, the aim is to allow for more modeling flexibility (in this case, that of neural variability) while retaining interpretability, which in this case corresponds to having a low-dimensional, visualizable latent space, even though the actual neural data is high-dimensional and non-linear.
Neural data and notation
In neural data, signals take the form of ms spikes that are modeled as discrete events. For data analysis, time is discretized into small bins of length , and the response of a population of neurons at time is represented by a vector of length . As spike responses are variable under identical experimental conditions, usually many repeated trials, , of the same experiment are recorded. We therefore denote
as spike counts of neurons for time and trial . We then also refer to when suppressing the time index, and to denote all the observations. Similar notation is used for other temporal variables.
fLDS generative models
Latent factor models are commonly used in neural data analysis, and attempt to infer latent trajectories which are low-dimensional () and evolve in time. One approach takes inspiration from the Kalman filter, so that the latent states evolve according to
where , and are covariance matrices. In fLDS, the observation model is given by
where
- is a noise model with parameter ,
- is an arbitrary continuous function.
Here, is represented through a feed-forward neural network model, so the parameters amount to weights/biases across units and layers. The aim is to then learn all the generative model parameters, which are denoted by .
Fitting via Auto-encoding Variational Bayes (AEVB)
Due to the noise model and the non-linear observation model, the posterior is intractable and so the authors employ a stochastic variational inference approach. The posterior is then approximated by a tractable distribution depending on parameters and the corresponding evidence lower bound (ELBO) is maximized; here, an auto-encoding variational Bayes approach is used to estimate . Given these, the ELBO is then maximized via stochastic gradient ascent.
This approach ends up being similar to that of the first paper, when considering the choice of approximate posterior distributions used. Here, a Gaussian approximation is used:
where and are parameterized by the observations through a structured neural network. This idea is similar to that in the SVAE paper, where we approximate the observation model by an exponential family conjugate to the model for the local latent variables with a diverse class of potential functions; here, we approximate the posterior for the latent variables by the conjugate family to that of the prior with a similarly diverse class of potential functions.
Experiments
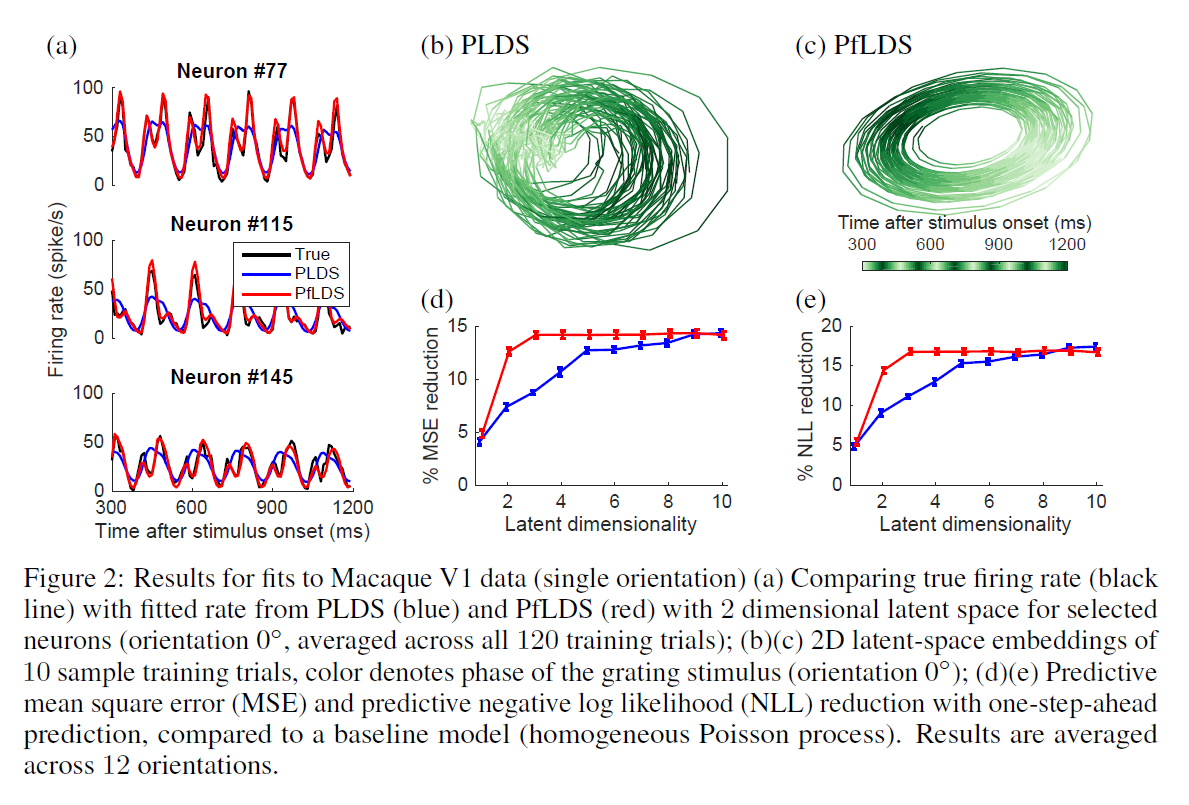
The above model is applied to various simulation and real data; we briefly describe one of the real data examples provided in the paper. Here, they look at neural data obtained from an anesthetized macaque, which was taken while the monkey watched a movie of a sinusoidal grating drifting in one of 72 orientations (starting from 0 degrees and incrementing in 5 degree steps). They then compare PfLDS (a fLDS with Poisson noise model) with a PLDS (Poisson LDS) using both a single orientation (0 degrees) and the full data, using a fraction of the data for training before assessing model fitting by one-step-ahead prediction on a held-out dataset. The figure below illustrates the performance of the two models when looking at single-orientation data; we can see that PLDS requires 10 latent dimensions to obtain the same predictive performance as a PfLDS with 3 latent dimensions - the PfLDS leads to more interpretable latent-variable representations.
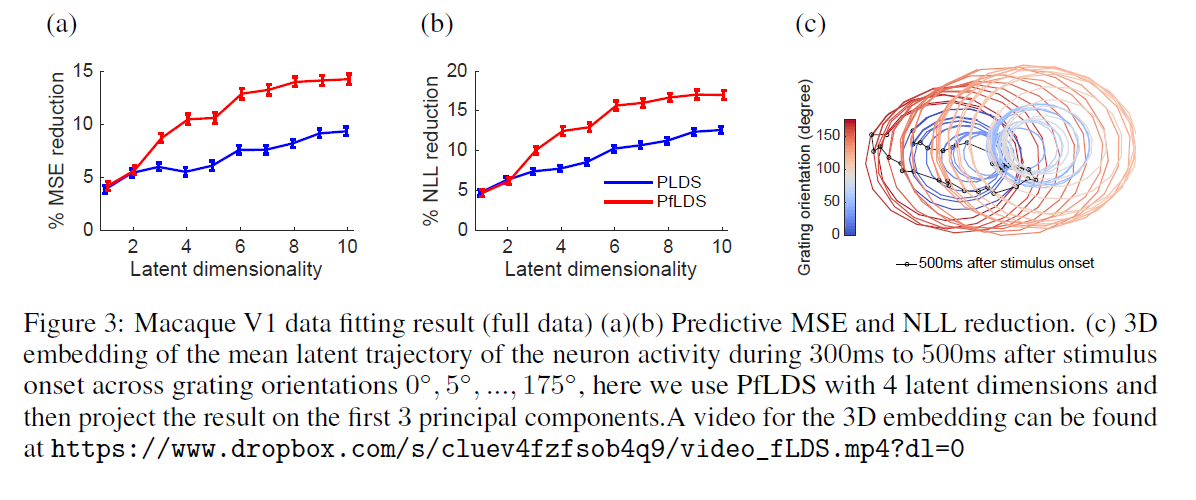
For the full orientation data, the below figure illustrates this principle again - that it provides better predictive performance with a small number of latent dimensions.
References
[1] Johnson, Matthew J., et al. “Composing graphical models with neural networks for structured representations and fast inference.” Advances in Neural Information Processing Systems (2016). link
[2] Gao, Yuanjun, et al. “Linear dynamical neural population models through nonlinear embeddings.” Advances in Neural Information Processing Systems (2016). link