This week, with the lead of Yuanjun Gao, we discussed two papers, “Human-level concept learning through probabilistic program induction.” by Lake et al [1] and “One-Shot Generalization in Deep Generative Models.” by Danilo J. Rezende et al [2]. The papers aim to mimic humans’ ability to learn from small numbers of examples. The first paper introduces Bayesian Program Learning framework (BPL)—a probabilistic model which allows such learning ability—and the second paper implements the idea in deep generative model.
The figures below are taken from the aforementioned papers.
Human Level Concept Learning
The motivation of one shot learning is clear from the introduction of Lake’s paper [1], “People can learn a new concept from just one or a handful of examples, whereas standard algorithms in machine learning require tens or hundreds of examples to perform similarly.” The paper expresses this learning by three abilities. Given a single object, human can:
- Classify new examples,
- Generate new examples of similar type,
- Parse it into parts and understand their relation.
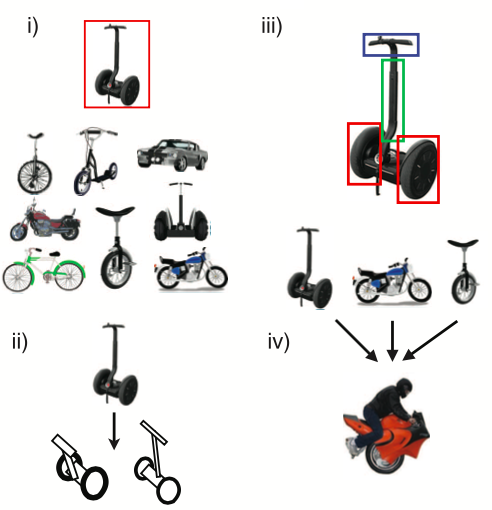
An example in Figure 1 of [1] (figure above) describes it well. When a single object in the red box of (i) is given, it is possible to classify objects below, whether it is a similar type or not. Also, human can create similar examples as in (ii). Human can also parse it into three smaller parts as in (iii) and fantasize new examples as in (iv).
Bayesian Program Learning
The paper introduces the Bayesian Program Learning (BPL) framework, which allows an algorithm to obtain the abilities described above. The BPL framework is based on three fundamental ideas:
- Compositionality
- Causality
- Learning to learn
The BPL approach learns simple stochastic programs to represent concepts, building them compositionally from pars, subparts, and spatial relation [1]. The joint distribution on types , a set of M tokens of that type, , and corresponding images, can be represented as:
Example with Hand Written Characters
The BPL and its fundamental ideas are more easily understood with a provided example. Let us say that we are learning a new set of hand written characters with few examples. Characters can be parsed based on strokes initiated by pressing a pen down and terminated by lifting it up (defined as “part” in figure below). Then, each stroke can be further separated by brief pauses of pen (“subpart” in figure below). If a character, “B”, is given, “B” can be parsed into two parts: one stick and another with two curves. Also, the second part can be further broken into a set of two half circles.
In this model, a generation of hand written characters can be described using a generative process. The process can be divided into type generation and token generation, which is shown in Figure 3 of [1].
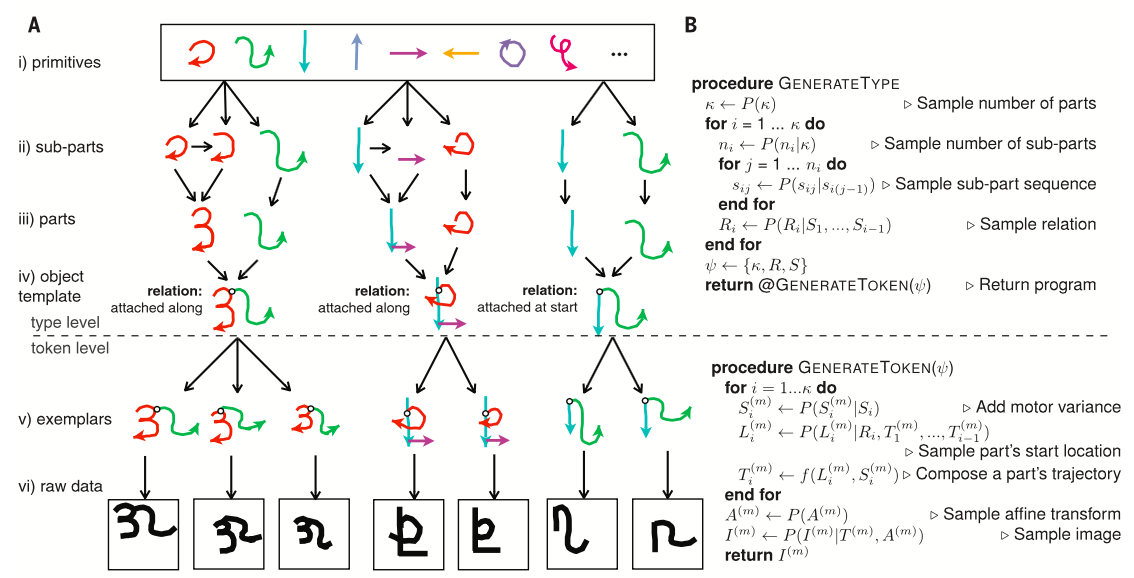
In words, Type Generation Process is:
- Determine the number of parts.
- For each part, determine number of subparts (condition on the number of parts).
- For each subpart, sample actual symbols from primitives “sequentially” (condition on the previous subpart). It completes each part.
- For each part, sample the relation of each part (condition on the part and the previous parts). An example of relation is “at which point of previous parts, the part should be attached”.
- Relations and Parts define a type of character
Given, a type, an actual image of hand written character is generated (Token and Image Generation Process) by the following (modeling how ink flows when someone write a character!):
- For each part, add a motor variation (since a hand written character looks slightly different every time).
- For each part, sample a start location sequentially, condition on its relation and trajectories of previous parts.
- For each part, a trajectory is sampled, condition on its shape and start location.
- Add global transformation
- An image is created by a stochastic rendering function, lining the stroke trajectories with grayscale ink and interpreting the pixel values.
The example above explains the three fundamental idea of BPL well. A character can be considered as constructed compositionally from simple primitives (“B” is constructed from one stick and half circle). The fact that it is parsed based on stroke and pauses captures natural causal structure of real world processes. Also the model learns to learn by “developing hierarchical priors which allow previous experience to ease learning of new concept” [1]. (Analyzing “B” learns new, primitives and relations, which can be later used to learn other characters easily).
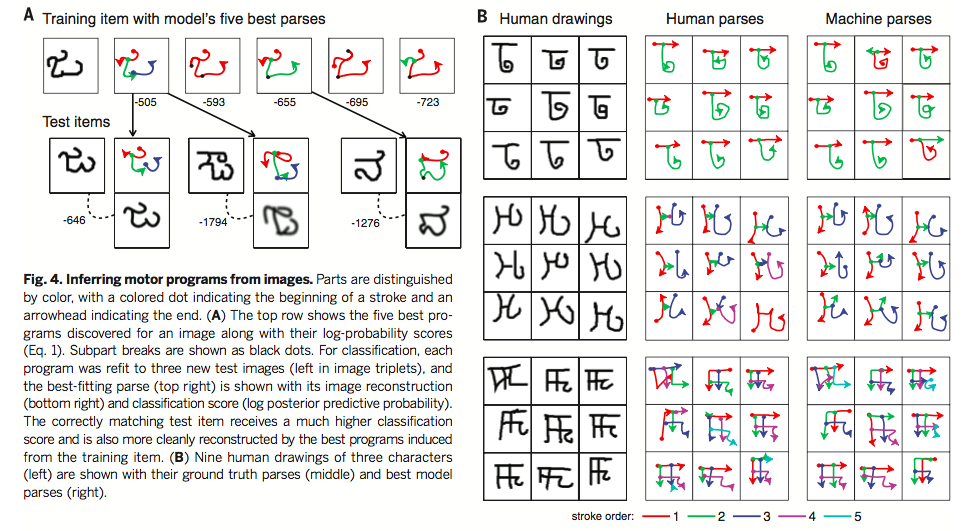
Figure 4 of [1] (below) shows how BPL learns a new figure by parsing it. The left panel shows the best five learned parsings given an example and how it is used to refit a new example. The right panel compares the machine parsing to the ground truth, which is how human would parse them.
Compare to Human Abilities
Classification of New Examples
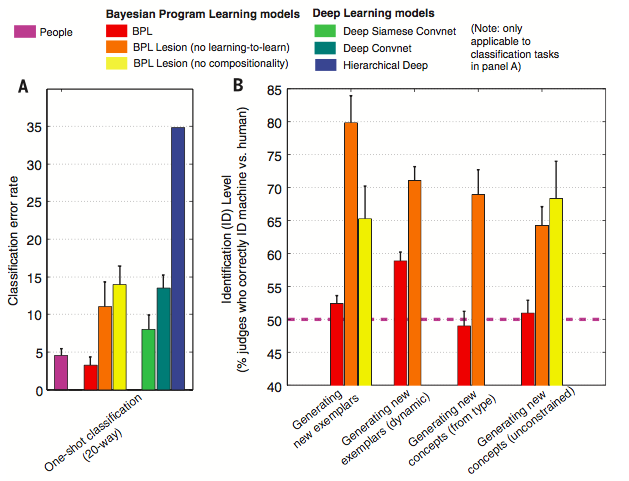
Given a single image of a new character, the classification task is to select images of the same type from 20 distinct characters. The result is shown in Figure 6A of [1] (figure below). BPL and Human showed similar error rate (3.3% and 4.5%).
The paper also tried the same tasks after “lesioning” certain parts of the algorithm. For example, lesionin the “Learning-to-learn” step removes the no type generative process and causes 11% error rate. Lesion the “Compositionality” step requires each character to be learned using only a single stroke, and causes 14% error. These results indicate how fundamental those two ideas are in the BPL.
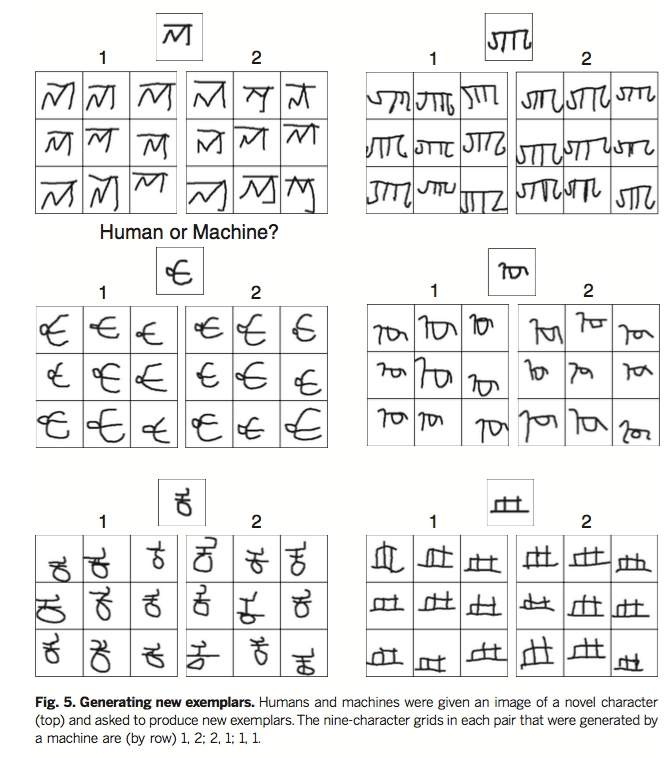
Generation of New Examples/Concepts
A “Visual Turing Test” is performed to examine this ability. Given an example character, both human and BPL created a set of new examples. Then, participants judged which set is created by human (or machine). The newly created examples are shown in Figure 5 of [1]. As shown, it is very hard to distinguish between them. You can check the answer at the end of figure caption. The result of experiment is shown in Figure 6 B of [1] (figure above). Since it is a Turing test, 50% of Identification (ID) level indicates that two cases are hard to distinguish. The judges only had 52% ID level on average.
To examine parsing more directly, the judges are shown with the movies of drawing characters. The result was 59% ID level. Also, the same experiment but generating new concepts, instead of new examples, is tested. The BPL achieved near 50% ID level in those too.
Parsing an object into parts and understand their relation
As shown in figure 4 of [1] (the third figure from the top), the BPL’s parsing ability is fairly reasonable and comprable to human parses.
Discussion
The BPL’s ability to understand structure in visual concepts is still very limited. It lacks the knowledge of parallel lines, symmetry, optional elements such as cross bars, and many others. It also lacks humans’ ability to use learned concepts for other tasks such as planning, communication, and conceptual combination [1]. However, for humans, these are learned from many years of education. One-shot learning and generalization of such seems not to be an easy task. The paper also mentions the hope for neural representations of concepts and the development of more neurally grounded learning models, which leads to the next paper.
One-Shot Generalization in Deep Generative Models
In this paper, it uses a deep generative model to allow one-shot generalization learning of images. It is built on the principles of feedback and attention.
The Model
Attention
It incorporates attention mechanism to learn images. In this paper, spatially-transformed (ST) attention process [3] is implemented, which is invariant to shape and size. It processes an input image using parameters to generate an output:
where and are 1-dimensional kernels, is the tensor outer-product of the two kernelts and indicates a convolution.
Sequential Generative Models
The following mathatical expression and Figure 2 of [2] (shown below) describe the model succinctly:
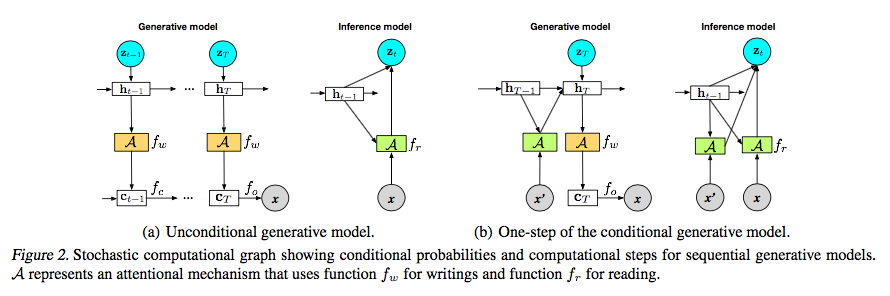
In each step , a -dimensional latent variables, , is sampled independently. An external context or piece of side information can be incorporated using an attentional mechanism.
The model is a generalization of existing models such as DRAW [4], composited VAEs [5], and AIR [6]. However, it introduces hidden canvas step, which allows pre-image to be constructed in a hidden space. Another note is that it allows the model be sampled without feeding-back the result of the canvas to the hidden state , which provides more efficiency.
Its ability to generate samples is shown in different dataset. As an example, the result of sample generation from the binarized MNIST data set is shown below.
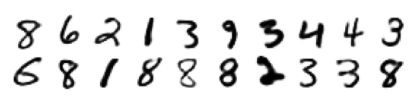
Use in One-shot Generalization
Generation of new examples or new types given small samples is demonstrated in this paper using the above generative model. It is similar to the ability described in the paper above. However, instead of producing examples by learning a single image (or small amount of images), the model generates new examples of a single type which is not part of training set. To do this, it uses a conditional generative model as shown in figure 2b of [2] or “context” section of the generative process.
Generation of New Examples
The paper tested the ability on two different cases.
- The model is trained using all available alphabets. But three characters from each alphabet are removed to form test set.
- Among 50 alphabets, 30 of them are used for training and 20 of them are used for testing. Alternative train-test data split, 40-10, and 45-5 are also performed.
The results are shown below (figure 9 and 10 of [2]) and the train and test log-likelihood is also compared in different train-test data split cases.


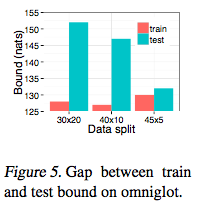
Figure 5 of [2] shows that there is small difference in train and test log-likelihood of 45-5 split, but it is rather presented in other cases. It indicates that overfitting is presented with small training dataset. However, the resulting characters show that even in the situation of over-fitting, it generates reasonable new examples.
Generation of New Types
The paper also tested if the process can generate new types by showing one character image. The result is shown in Figure 11 of [2]. (The result is subjective.)

Discussion
The paper uses deep generative processes to mimic human’s one-shot generalization ability. It shows that the process can generate new examples or new types when unseen examples are provided. Compared to the BPL model by Lake [1], which uses naturally occurring causal structures of objects, this method is applicable to many settings. However, there are few limitations, which can lead to future study. It still needs reasonable amount of data to avoid overfitting. While it is applicable to any images (by not using specific structures), it cannot parse structures into smaller parts.
References
[1] Lake, Brenden M., Ruslan Salakhutdinov, and Joshua B. Tenenbaum. “Human-level concept learning through probabilistic program induction.” Science 350.6266 (2015): 1332-1338. link
[2] Rezende, Danilo, et al. “One-Shot Generalization in Deep Generative Models.” Proceedings of The 33rd International Conference on Machine Learning. 2016. link
[3] Jaderberg, M., Simonyan, K., Zisserman, A., and Kavukcuoglu, K. Spatial transformer networks. In NIPS, 2015.
[4] Gregor, K., Danihelka, I., Graves, A., Rezende, D. J., and Wierstra, D. DRAW: A recurrent neural network for image generation. In ICML, 2015.
[5] Huang, J. and Murphy, K. Efficient inference in occlusion-aware generative models of images. arXiv preprint arXiv:1511.06362, 2015.
[6] Eslami, S. M., Heess, N., Weber, T., Tassa, Y., Kavukcuoglu, K., and Hinton, G. E. Attend, Infer, Repeat: Fast scene understanding with generative models. arXiv preprint arXiv:1603.08575, 2016.