In this week’s session we read and discussed two papers relating to GANs: Wasserstein GAN (Arjovsky et al. 2017 [1]) and Adversarial Variatonal Bayes: Unifying Variational Autoencoders and Generative Adversarial Networks (Mescheder et al. 2017 [4]). The first paper introduces the use of the Wasserstein distance rather than KL divergence for optimization in order to counter some of the problems faced in original GANs. The second paper synthesizes GANs with VAEs in an effort to allow arbitrarily complex inference models.
The figures and tables below are copied from the aforementioned papers.
Review of GANs
GANs were introduced by Goodfellow et al. in 2014 [2] as an alternative to the maximum likelihood approach to generative models. In a maximum likelihood framework, we define a distribution over our data and choose parameters such that the likelihood of the training data is maximized: .
In a GAN framework, the problem is formulated as a minimax game between a generator function G, and a discriminator function D. The classic analogy for this is that of a counterfeiter and a policeman. The policeman (D) tries to maximize his ability to distinguish between counterfeit products and real products, while the counterfeiter (G) simultaneously tries to produce material that is as close to the real deal as possible.
Define the following notation:
- - the true data generating distribution
- - prior on the latent variables
- - the distribution over fake generated data,
Setting this up as a minimax game, D is trained to maximize the probability of assigning to the real data rather than the generated data , while G is trained to minimize the discrepancy between the real data and the generated data. The value function is given by:
To optimize this, the following updates are used:
- (D) Discriminator
- (G) Generator
The optimal discriminator for any generator can be shown to be: [2]. Plugging this in to the value function for the game,
where JS is the Jenson-Shannon divergence.
Problems with GANs
- Unstable training: It is hard to balance between optimizing G and D
- Collapse of the mode, also called mode dropping
- High dependency on the architecture of the NN
- Hard to quantify how well a model does outside of an arbitrary “these generated pictures look good”
Wasserstein GAN
This paper overcomes some of the problems with the original GANs through the introduction of an alternative metric to KL divergence. When looking at distributions over low dimensional manifolds, the chance of their having overlapping support is low, resulting in an undefined or infinite KL divergence. The Earth-Mover, or Wasserstein-1, distance is defined as the cost of the optimal transport plan:
The name “Earth-Mover” can be understood by thinking of each distribution as a pile of dirt, with the EM distance defined as the amount of dirt that needs to be moved times the distance it needs to be moved.
In Example 1 of [1], this paper presents two distributions with a negligible intersection in order to highlight the problems that arise when using KL and JS divergence. Take and define to be the distribution of . Let be the distribution of . Some commonly chosen metrics in this case are:
- Wasserstein or “Earth-Mover”:
- Jensen-Shannon: if , otherwise
- Kulback-Leibler: if , otherwise
As , converges to under the EM distance, but not under the JS or KL distances. The JS and KL distances are not even continuous in this instance. The authors formalize this idea in in Theorem 1 [1], providing continuity results for the EM distance that motivate the choice of using this as a loss function.
To optimize over instead of , something must be done about the intractable infimum present in the definition of Wasserstein distance. Enter the handy Kantorovich-Rubinstein duality. Using this duality, the EM distance can be reformulated as , where the supremum is over all 1-Lipschitz functions.
The Wasserstein GAN (WGAN) is then optimized through the following updates:
- (D)
- (G) where are weights that parameterize a neural network. To ensure lie in a compact space, the weights are clamped to .
Solving this optimization problem is done through the algorithm described below:

The weight constraint prevents the discriminator from saturating by limiting D to grow at most linearly. The continuity and differentiability of the EM distance allows D to be trained to optimality, preventing the modes from collapsing as before.
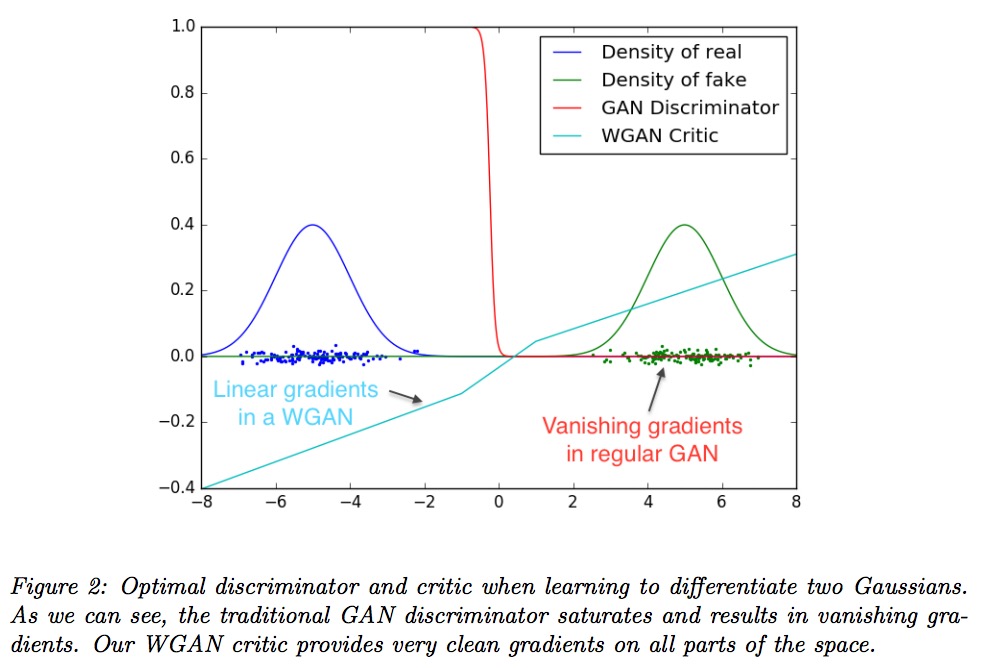
In the experiments section, the authors confirm their assertions, even bringing out the bold font in Section 4.3 to emphasize their circumvention of mode collapsing. It is also important to note that the nonstationarity of D results in a worse performance for momentum based methods like Adam, causing them to use RMSProp instead.
Adversarial Variational Bayes
This paper presents an adversarial procedure for training Variational Autoencoders ([3]) that uses the flexibility of neural networks to allow arbitrarily complex inference models.
Review of VAEs
Consider data generated from some distribution over latent continuous variables . We are interested in the true posterior density . This distribution is often intractable, and so we approximate it with an approximate inference model, . We wish to choose the model that minimizes the KL divergence between the approximate posterior and the true posterior:
A common result in variational inference bounds the marginal likelihood of by the variational lower bound (or ELBO):
This lower bound is used to define the objective function we wish to optimize:
AVB
This paper starts by rewriting the objective function in the following form:
Ideally, we want to be arbitrarily complex. But if is defined through a black-box procedure, it can no longer be optimized using the reparameterization trick and stochastic gradient descent, as in the VAE set-up [3]. To get around this, the authors define a discriminative network that is optimized simultaneously.
The objective function for is as follows:
where is the sigmoid function. In this way is optimized to distinguish between pairs sampled independently from and those sampled from the current model . The optimal discriminator for this objective is shown to be . The new objective function is then,
In Proposition 2, the authors show that the gradient of with respect to satisfies . Therefore, taking the gradients with respect to and $\phi$ is straightforward. Using the reparameterization trick of [3], the AVB algorithm alternates between optimizing the objective function and the discriminative network :

As in the original GAN setup, the optimal discriminator can be shown to be: . By allowing and to be arbitrarily complex, Corollary 4 proves that the game will recover the ML estimate . Additionally, Corollary 4 proves that is the pointwise mutual information between and .
The experiments indicate an improvement between VAE and AVB on a variety of generative tasks. Their performance on a toy example is seen below:
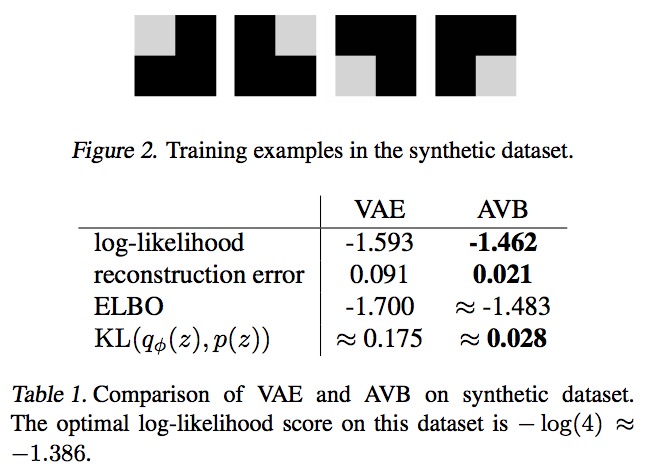
For a nice implementation of this example, see here.
References
[1] Arjovksy, et al. “Wasserstein GAN.” arXiv preprint arXiv:1701.07875 (2017). link
[2] Goodfellow, et al. “Generative Adversarial Networks.” Advances in Neural Information Processing Systems (2014). link
[3] Kingma, et al. “Auto-Encoding Variational Bayes.” International Conference on Learning Representations (2014). link
[4] Mescheder, et al. “Adversarial Variational Bayes: Unifying Variational Autoencoders and Generative Adversarial Networks.” arXiv preprint arXiv:1701.04722 (2017). link